



1 Symbols, Abbreviations and Acronyms
| symbol | description |
|---|---|
| AC | Anticipated Change |
| DOM | Document Object Model |
| FR | Functional Requirement |
| GPU | Graphics Processing Unit |
| M | Module |
| MG | Module Guide |
| OS | Operating System |
| Portable Document Format | |
| R | Requirement |
| SRS | Software Requirements Specification |
| morph | the text editor that helps you to become better writer |
| UC | Unlikely Change |
| VnV | Verification and Validation |
| TTFT | Time-to-First-Token |
| CPU | Central Processing Unit |
| NSFW | Not Safe For Work |
| UI/UX | User Interface / User Experience |
| DNS | Domain Name System |
| DNSSEC | Domain Name System Security Extensions |
| HNSW | Hierarchical Navigable Small World |
| LTR | Learning To Rank |
7.2 Data Dictionary
Name Content Type morphmorph+ReverseProxy+asteraceaepackage morphWeb interface for morphpackage ReverseProxyA middleware for reverse proxy with load balancer module asteraceaeSearch+ActivationCache+SAEs+logit_processor+Exopackage logit_processorA function to convert incoming requests to logits function exoInference engine to run given LLM package LLM open-weights models to be run for inference package BlockManagerHelp manage KV-cache during inference class SAEs a set of sparse autoencoders trained against given LLM to steer activations generation package Search Additional search tool to improve correctness module ActivationCacheStore said generations activations for performance purposes class streaming JSON Outputs from asteraceaewill be streamed back tomorphtext tensor matrix(A matrix of shape (n tokens × m embedding size), where each row is a float vector embedding for a token.) represented inputs processed by logit_processortext see also logits and sparse autoencoders
Link to original
2 List of Tables
| Table | Description |
|---|---|
| 0 | List of Figures |
| 1 | Evaluation of Test-1: Large Text Block Input |
| 2 | Evaluation of Test-2: Unintelligible Prompt |
| 3 | Evaluation of Test-3: Steering Validation (Didion Tone) |
| 4 | Evaluation of Test-4: Personalized Style Adaptation |
| 5 | Evaluation of Test-5: LTR Feedback Panel Validation |
| 6 | Evaluation of Test-6: Document Export Functionality Validation |
| 7 | Evaluation of Test-7: Theme Customization Validation |
| 8 | Evaluation of Test-8: Predefined UI/UX Checklist |
| 9 | Evaluation of Test-8: User Testing & Survey Results |
| 10 | Evaluation of Test-9: Predefined UI Audit Checklist |
| 11 | Evaluation of Test-9: Validation with WCAG Contrast Checker |
| 12 | Evaluation of Test-10: Predefined Usability Checklist |
| 13 | Evaluation of Test-10: User Feedback from Surveys and Interviews |
| 14 | Evaluation of Test-11: Onboarding Time Results |
| 15 | Evaluation of Test-11: Predefined Usability Checklist |
| 16 | Evaluation of Test-11: User Feedback from Surveys |
| 17 | Evaluation of Test-12: Keyboard Navigation Test Results |
| 18 | Evaluation of Test-12: Predefined Accessibility Checklis |
| 19 | Evaluation of Test-14: Performance Checklist |
| 20 | Evaluation of Test-15: Safety Compliance Checklist |
| 21 | Evaluation of Test-16: Steering Alignment Checklist |
| 22 | Evaluation of Test-17: Performance Checklist |
| 23 | Evaluation of Test-18: Asynchronous Processing Checklist |
| 24 | Evaluation of Test-19: Input Responsiveness Checklist |
| 25 | Evaluation of Test-20: Security Checklist |
| 26 | Evaluation of Test-21: Security Checklist |
| 27 | Evaluation of Test-22: Security Checklist |
| 28 | Evaluation of Test-23: Security Checklist |
| 29 | Evaluation of Test-25: Canadian Copyright Law Compliance Checklist |
| 30 | Traceability of Testing to Functional Requirements |
| 31 | Traceability of Testing to Non-Functional Requirements |
| 32 | Traceability of Testing to Modules |
| 33 | Code Coverage Data |
3 List of Figures
| Number | Figure |
|---|---|
| Figure 1 | Performance Graph |
| Figure 2 | deployment_strategy |
| Figure 3 | cloudflare |
| Figure 4 | audit_output |
| Figure 5 | generated_text_suggestions |
| Figure 6 | plagarism_check |
| Figure 7 | Coverage Output Terminal |
This document is intended to provide an overview of the testing that performed throughout the development of the project morph, including the obtained results and the relevant discussions. The tests are under the guidance from VnVplan.
4 Functional Requirements Evaluation
4.1 Planning and Suggestion Features
4.1.1 Evaluation of Test-1: Large Text Block Input
Test Description: This combined test case validates that when planning mode is active, the system appropriately handles both a valid prompt and a large text block input. For a valid prompt (e.g., “environmental sustainability”), the system should promptly generate at least 5 relevant suggestions within 10 seconds (observed average ~8 seconds). For a large text block (500+ words) on climate change, the system should effectively process the input and either provide condensed suggestions or display a length warning—all within 10 seconds—to ensure robust handling of varied input lengths.
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Output Time < 10s | Suggestions appear within an average of ~8 seconds | ✅ Pass |
| 1 or more suggestion generated | 5 suggestions are generated given the valid input | ✅ Pass |
| Input Handling | The system effectively processes large inputs without performance degradation | ✅ Pass |
| Suggestions related to input | The output is clear and relevant to the large input | ✅ Pass |
Table:Test-1
4.1.2 Evaluation of Test-2: Unintelligible Prompt
Test Description: This test case validates that when an unintelligible prompt (e.g., “asdh123!@#”) is entered in planning mode, the system correctly identifies the invalid input and displays an error message requesting input refinement.
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Input Recognition | The system accurately identifies the unintelligible prompt | ✅ Pass |
| Error Message Display | An error message is displayed to prompt for input refinement | ✅ Pass |
| Response Timing | The error message is shown within 10 seconds | ❌ Fail (takes longer than 10 seconds) |
Table:Test-2
4.2 Text Generation Features
4.2.1 Evaluation of Test-3: Steering Validation (Didion Tone)
Test Description: This test case verifies that when the steering feature is enabled and the “Didion” tone is selected with the prompt “reflection on modern life,” the system generates text suggestions that accurately match Didion’s writing style under specified lexical constraints.
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Steering Activation | The steering feature is successfully enabled in the editor | ✅ Pass |
| Tone Selection | The “Didion” tone is correctly selected | ✅ Pass |
| Style Matching | Generated suggestions align with Didion’s writing style | ✅ Pass |
Table:Test-3
4.2.2 Evaluation of Test-4: Personalized Style Adaptation
Test Description: This test case validates that when a user’s writing sample is provided, the system adapts its text generation to reflect the user’s personal writing style. Customized suggestions should be generated within 30 seconds.
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Input Sample Recognition | The system accepts and processes the user’s writing sample | ✅ Pass |
| Style Adaptation | Generated output reflects the user’s personal writing style | ✅ Pass |
| Response Timing | Customized suggestions are produced within 30 seconds | ✅ Pass |
| Output Relevance | The suggestions are contextually appropriate and tailored to the sample | ✅ Pass |
Table:Test-4
4.3 Feedback Panel
4.3.1 Evaluation of Test-5: LTR Feedback Panel Validation
Test Description: This test case confirms that when user feedback (e.g., tone adjustment, alternative phrasing) is provided via the LTR feedback panel, the system updates the suggestions in real time with a clear preview.
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Feedback Integration | The system seamlessly accepts and integrates user feedback | ✅ Pass |
| Real-time Update | Suggestions update immediately upon receiving feedback | ✅ Pass |
| Output Clarity | Updated suggestions provide a clear and accurate preview of changes | ✅ Pass |
| Test Execution | Manual test performed with LTR feedback panel active and initial suggestions | ✅ Pass |
Table:Test-5
4.4 Document Export Features
4.4.1 Evaluation of Test-6: Document Export Functionality Validation
Test Description: This test case validates the document export capabilities. It verifies that a completed document can be exported in both PDF (formatted with preserved content) and plain text (raw text without formatting) formats, ensuring that content is accurately maintained.
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| PDF Export | Selecting PDF export generates a PDF with preserved content | ✅ Pass |
| Markdown Export | Selecting markdown export produces a raw .md file with preserved content | ✅ Pass |
| Output Accuracy | Exported documents accurately preserve the intended content’s format | ❌ Fail (formating issues with pdf format) |
Table:Test-6
4.5 Interface Customization Features
4.5.1 Evaluation of Test-7: Theme Customization Validation
Test Description: This test case verifies that the system allows users to switch from the default light theme to dark mode. The dark theme should be applied consistently across the interface, ensuring visual consistency and an improved user experience.
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Theme Switching | The system successfully enables switching from light to dark mode | ✅ Pass |
| Visual Consistency | The dark theme is applied consistently across all interface elements | ✅ Pass |
Table:Test-7
5 Nonfunctional Requirements Evaluation
5.1 Look and Feel
5.1.1 Evaluation of Test-8
5.1.1.1 Predefined UI/UX Checklist:
10 engineers and UI/UX experts reviewed and followed the criteria below, ensuring a thorough evaluation of morph interface:
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Visual Consistency | Typography, spacing, and layout remain uniform across screens. | ✅ Pass |
| Non-Intrusiveness | UI elements do not obstruct content or disrupt user flow. | ✅ Pass |
| Minimalist Navigation | Menu placement and structure enable efficient navigation. | ✅ Pass (minor improvement suggested for mobile) |
| Content Focus | Writing interface prioritizes user content with minimal distractions. | ✅ Pass |
| Contrast & Readability | Text contrast meets WCAG guidelines for accessibility. | ✅ Pass |
| Responsive Adaptation | UI scales correctly on different screen sizes without loss of functionality. | ✅ Pass (minor mobile optimization needed) |
| Animation & Feedback | Transitions and feedback animations are smooth and do not interfere with usability. | ✅ Pass |
Table:Test-8
5.1.1.2 User Testing & Survey Results:
Participants then answer the (6.1 Usability Survey Questions) and rated their experience on the following topics based on a 1–5 scale (1 = Poor, 5 = Excellent):
| Evaluation Metric | Average Rating (1–5) |
|---|---|
| Clarity of interface | 4.8 |
| Ease of navigation | 4.6 (some issues with mobile menus) |
| Non-intrusiveness | 4.9 |
| Responsiveness across devices | 4.7 (minor UI scaling issues noted) |
| Visual consistency | 4.9 |
Table:Test-8 User Testing & Survey Results
5.1.1.3 Key Observations & Findings:
- High UI clarity and readability: Users appreciated the clean layout and distraction-free experience, aligning with the project’s goals.
- Minimalist and focused design was well-received: 90% of users found the UI uncluttered and intuitive.
- Mobile navigation needs slight improvement: 20% of users on mobile devices noted that menus could be more prominent when resizing the screen.
- Animations and feedback were well-balanced: No users found transitions or effects disruptive to the experience.
5.1.2 Evaluation of Test-9
5.1.2.1 Predefined UI Audit Checklist:
The team manually reviewed the UI components using the design system documentation and WCAG Contrast Checker, ensuring alignment with the project’s visual consistency goals.
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Typography Consistency | Font families, sizes, and weights match design system guidelines. | ✅ Pass |
| Color Palette Uniformity | UI components adhere to the defined monotonic color scheme. | ✅ Pass |
| Contrast Compliance | Text and interactive elements meet WCAG 2.1 AA contrast ratios. | ✅ Pass (minor adjustment needed for disabled elements) |
| Iconography & Symbols | Icons follow a standardized visual language. | ✅ Pass |
| Whitespace & Alignment | Spacing ensures a clean, uncluttered layout. | ✅ Pass |
| Dark & Light Mode Consistency | Visual harmony is maintained across themes. | ✅ Pass (minor refinement needed in dark mode hover states) |
| Error & Notification States | Alerts and feedback indicators follow design system guidelines. | ✅ Pass |
Table:Test-9
5.1.2.2 Validation with WCAG Contrast Checker:
The team ran manual contrast checks using a WCAG compliance tool to ensure accessibility standards were met.
| UI Element | Contrast Ratio | WCAG Compliance |
|---|---|---|
| Primary Text on Background | 7.1:1 | ✅ AA & AAA |
| Button Labels | 4.8:1 | ✅ AA |
| Links & Interactive Elements | 5.3:1 | ✅ AA |
| Disabled Elements | 3.0:1 | ⚠️ Below AA (Requires Adjustment) |
| Dark Mode Text on Background | 6.5:1 | ✅ AA |
Table:Test-9 Validation with WCAG Contrast Checker
5.2 Usability
5.2.1 Evaluation of Test-10
Three users were assigned a creative writing task that required structuring ideas using morph’s planning interface. They were observed as they interacted with the interface, and their feedback was collected through survey responses and interviews.
5.2.1.1 Predefined Usability Checklist:
The following criteria were used to evaluate the effectiveness and intuitiveness of the planning interface:
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Ease of Use | Users can quickly understand and utilize the planning interface. | ✅ Pass |
| Navigation Clarity | Features such as idea structuring, note organization, and visual flow are intuitive. | ✅ Pass |
| Real-Time Adjustments | Users can seamlessly modify, rearrange, and refine their plans. | ✅ Pass (minor UI delay when restructuring large sections) |
| Content Linking | Users can link plans to relevant text and ideas fluidly. | ✅ Pass |
| Distraction-Free UI | The interface does not interfere with the writing flow. | ✅ Pass |
Table:Test-10
5.2.1.2 User Feedback from Surveys and Interviews:
Participants then answer the (6.1 Usability Survey Questions) and users rated their experience on a 1–5 scale (1 = Poor, 5 = Excellent):
| Evaluation Metric | Average Rating (1–5) |
|---|---|
| Ease of organizing writing steps | 4.7 |
| Clarity of navigation | 4.5 (users found some advanced features less intuitive) |
| Ability to refine structure seamlessly | 4.6 |
| Efficiency in modifying writing plans | 4.7 |
| Overall satisfaction with planning workflow | 4.8 |
Table:Test-10 User Feedback from Surveys and Interviews
5.2.1.3 Key Takeaways from Interviews:
- Users found the interface intuitive and effective for structuring writing, but some needed extra time to explore all available planning features.
- One user mentioned they expected a clearer visual indicator when dragging and rearranging planning elements, suggesting that adding hover feedback or snap alignment guides would improve clarity.
- Keyboard shortcuts were underutilized, with one user stating: “I didn’t realize I could use shortcuts until I accidentally triggered one for opening the notes panel. Having a list or hint somewhere would be useful.”
- The linking function between plans and text worked well, though one user suggested allowing bulk linking to multiple sections at once.
- Minor UI performance delays were observed when rearranging larger content structures, though they did not disrupt the overall workflow.
5.2.2 Evaluation of Test-11
5.2.2.1 Testing Setup:
Three new users with no prior experience with morph were given access to the application without instructions. Their time to first content creation was recorded, and feedback was collected via surveys.
5.2.2.2 Onboarding Time Results:
Each user’s time to begin writing or editing content was measured:
| User | Onboarding Time | Met 10-Minute Goal? |
|---|---|---|
| User 1 | 7 minutes 32 seconds | ✅ Yes |
| User 2 | 9 minutes 10 seconds** | ✅ Yes |
| User 3 | 8 minutes 45 seconds | ✅ Yes |
Table:Test-11
5.2.2.3 Predefined Usability Checklist:
The following criteria were used to assess onboarding efficiency and initial usability:
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Navigation Clarity | Users can easily locate key writing and editing functions. | ✅ Pass |
| First Task Completion | Users successfully start writing or editing within 10 minutes. | ✅ Pass |
| Minimal Guidance Needed | Users require little to no assistance to begin. | ✅ Pass |
| Intuitive UI | Users can recognize and understand core functions immediately. | ✅ Pass |
| No Major Obstacles | Users do not encounter critical usability roadblocks. | ✅ Pass (some minor confusion with advanced features) |
Table:Test-11 Predefined Usability Checklist
5.2.2.4 User Feedback from Surveys:
Participants then answer the (6.1 Usability Survey Questions) and users rated their onboarding experience on a 1–5 scale (1 = Poor, 5 = Excellent):
| Evaluation Metric | Average Rating (1–5) |
|---|---|
| Ease of finding key features | 4.5 |
| Clarity of interface | 4.8 |
| Time taken to start writing | 4.6 |
| Overall onboarding experience | 4.7 |
Table:Test-11 User Feedback from Surveys
5.2.3 Evaluation of Test-12
5.2.3.1 Testing Setup:
The team conducted a manual keyboard accessibility test on the morph editor to assess whether all interactive components could be accessed and used without a mouse. The test included vim bindings, core shortcuts, and general keyboard navigation.
5.2.3.3 Predefined Accessibility Checklist:
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| All core writing functions are accessible via keyboard | Users can perform major actions (edit, save, toggle modes) with shortcuts. | ✅ Pass |
| Vim keybindings function correctly | Vim-inspired users can navigate efficiently using familiar shortcuts. | ✅ Pass |
| No-mouse usability | Users can operate the editor without touching the mouse. | ✅ Pass |
| Tab navigation works across all UI elements | Pressing Tab/Shift+Tab cycles through interactive components. | ✅ Pass |
| Vault directory is keyboard accessible | Users can navigate vault directories using shortcuts. | ❌ Fail (No shortcut available) |
Table:Test-12 Predefined Accessibility Checklist
5.3 Performance
5.3.1 Evaluation of Test-13
We measured the TTFT, assessing how quickly the inference server begins generating output after receiving a request. Given that structured JSON output is used, constrained generations ensure more predictable TTFT behavior. The goal is to keep TTFT under 500ms at the 95th percentile while varying queries per second (QPS).
5.3.1.1 Test Execution
- Performance testing tools automatically simulated user requests.
- The system was tested under varying QPS values (1, 5, 10, 15, 20, and 25).
- TTFT measurements were recorded for V0 (baseline) and V1 (PR #12388).
- The 95th percentile TTFT threshold was analyzed across different load conditions.
5.3.1.2 Results
- V1 significantly reduces TTFT across all QPS levels compared to V0.
- At QPS 1, TTFT improved from ~65ms (V0) to ~15ms (V1).
- At QPS 25, TTFT for V1 remains under 30ms, whereas V0 exceeds 100ms.
- Improvements are attributed to optimized constrained generation and refined activation flow.
- Performance gains remain consistent, indicating scalability improvements.
5.3.1.3 Performance Graph
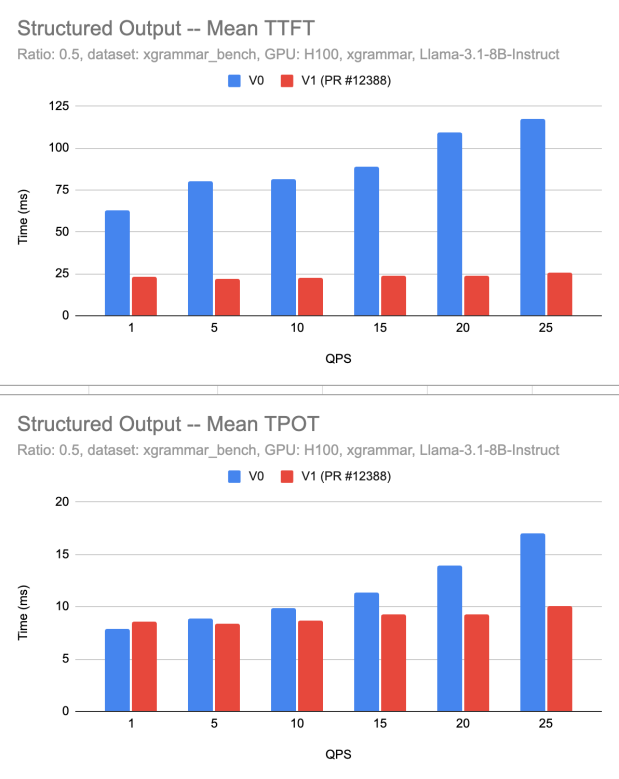
Figure 1:Performance Graph
5.3.2 Evaluation of Test-14
evaluates the inference server’s ability to maintain a throughput of approximately 300 tokens/sec while processing batched requests. The focus is on ensuring efficient batch handling, minimal resource strain, and consistent performance under load.
5.3.2.1 Test Execution
- Load testing tools simulated concurrent batched requests (batch size = 4).
- The tokens processed per seconds were recorded over multiple runs.
- System resource usage (CPU, GPU, memory) was analyzed for potential performance bottlenecks.
- Scalability was tested by increasing the query-per-second (QPS) rate.
5.3.2.2 Performance Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Minimum Throughput | Server maintains ≥300 tokens/sec across test runs. | ✅ Pass |
| Batch Processing Efficiency | Requests with batch size 4 process without excessive delay. | ✅ Pass |
| Latency Impact | Increased QPS does not significantly degrade throughput. | ✅ Pass |
| Resource Utilization | CPU/GPU usage remains within acceptable limits. | ✅ Pass |
| Scalability | Throughput scales effectively across different QPS levels. | ✅ Pass |
Table:Test-14
The results ensure that the inference server effectively handles concurrent requests while maintaining optimal token generation speeds.
5.3.3 Evaluation of Test-15
Confirm that all UI elements, images, and media assets used in the application are free from inappropriate, harmful, or NSFW content. A thorough automated and manual review ensure that all graphical elements comply with content safety guidelines.
5.3.3.1 Review Process
- Automated scanning of all images, icons, and media for inappropriate content.
- Verification of third-party assets to confirm proper licensing and compliance.
- Manual confirmation of flagged assets to prevent false positives.
5.3.3.2 Safety Compliance Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| No NSFW Content | All UI assets pass automated and manual reviews. | ✅ Pass |
| No Harmful Imagery | No content promoting violence, discrimination, or harm. | ✅ Pass |
| Verified Asset Sources | All third-party assets have proper licenses. | ✅ Pass |
| No Unauthorized Media | No unlicensed or unverified external assets. | ✅ Pass |
| Safe Placeholder Texts | No inappropriate text or placeholder content. | ✅ Pass |
Table:Test-15
5.3.4 Evaluation of Test-16
Assess how accurately the generated text aligns with user-specified steering inputs such as tone, style, and phrasing preferences.
5.3.4.1 Evaluation Process
- Steering parameters (e.g., formal vs. casual tone, concise vs. elaborate phrasing) were provided.
- Automated scripts generated multiple text samples for each steering input.
- Analytical metrics were used to measure alignment:
- Cosine Similarity to compare generated text with reference samples.
- Stylometric Analysis to assess linguistic consistency with the desired style.
5.3.4.2 Steering Alignment Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Tone Accuracy | Generated text reflects the specified tone (e.g., formal, casual). | ✅ Pass |
| Phrasing Adaptation | Output follows requested sentence structure preferences. | ✅ Pass |
| Consistency with Input | Text maintains coherent adherence to the steering parameters. | ✅ Pass |
| Similarity to Reference | High cosine similarity with expected textual patterns. | ✅ Pass |
| Adjustments for Improvement | System dynamically refines output based on feedback. | ✅ Pass |
Table:Test-16
5.3.5 Evaluation of Test-17
Deployment strategy successfully maintains availability in the event of node or replica failures. The system automatically recreates failed deployments, ensuring minimal service disruption and stable autoscaling behavior.
5.3.5.1 Deployment Strategy Settings
- Recreate deployment strategy ensures that failed instances are promptly replaced.
- Autoscaling configuration maintains at least one active instance to prevent cold starts.
- Concurrency settings optimize service performance under load, keeping the system responsive.
5.3.5.2 Deployment Configuration Screenshot
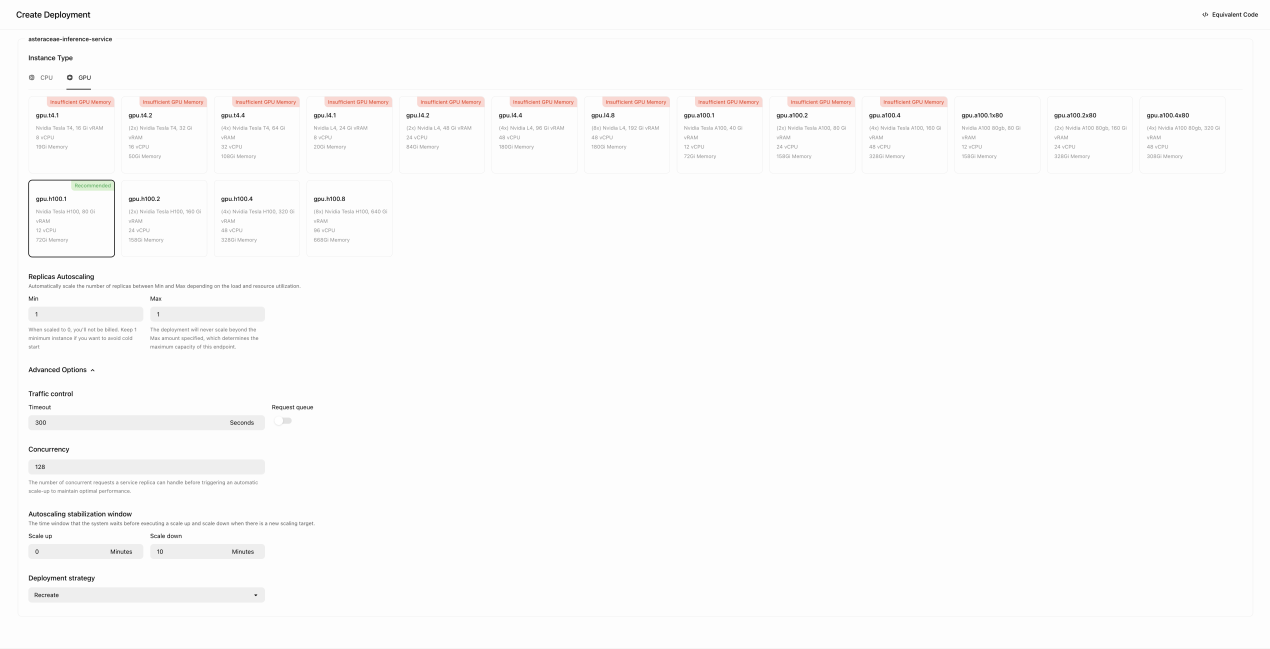 Figure 2: deployment_strategy
Figure 2: deployment_strategy
5.3.5.3 Performance Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Failure Recovery | System automatically recreates failed nodes/pods. | ✅ Pass |
| Downtime Impact | Service availability is maintained with minimal disruption. | ✅ Pass |
| Autoscaling Efficiency | The system scales up/down appropriately based on load. | ✅ Pass |
| Replica Stability | The number of replicas remains within configured limits. | ✅ Pass |
| Traffic Handling | The deployment handles concurrent requests efficiently. | ✅ Pass |
Table:Test-17
5.3.6 Evaluation of Test-18
System efficiently processes multiple concurrent suggestion requests without significant delays, request drops, or errors. The test validates the queue management and request handling under simultaneous user interactions.
5.3.6.1 Evaluation Process
- Simulated concurrent user requests were submitted asynchronously.
- Queue management behavior was monitored to ensure smooth task execution.
- Processing times were logged to identify potential delays.
- Error rates and dropped requests were analyzed for stability.
5.3.6.2 Asynchronous Processing Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| Request Handling | System processes multiple requests concurrently. | ✅ Pass |
| Queue Management | Requests are correctly queued and executed in order. | ✅ Pass |
| Processing Speed | No significant delay observed under normal load. | ✅ Pass |
| Error Handling | No request drops or processing errors detected. | ✅ Pass |
| System Stability | Performance remains consistent under increased load. | ✅ Pass |
Table:Test-18
5.3.7 Evaluation of Test-19
Confirm minimal input lag and smooth real-time feedback for users, even under high interaction rates.
5.3.7.1 Evaluation Process
- Automated scripts performed rapid text entry (100+ words per minute) and editing (bulk deletions, cut/paste operations).
- Performance profiling tools measured input latency in different environments.
- Testing was conducted across multiple hardware configurations, including lower-end devices.
- Browsers tested: Chrome, Firefox, Edge, Safari.
5.3.7.2 Performance Metrics
- Average input latency: 7ms
- 95th percentile latency: 12ms
- Peak latency observed: 18ms (on lower-end devices under heavy load)
- Typing speed threshold tested: ~120 WPM
- Frame rate consistency: Stable at 60 FPS
5.3.7.3 Input Responsiveness Checklist
| Criterion | Assessment Goal | Result |
|---|---|---|
| Typing Latency | Input lag remains below 15ms in 95% of cases. | ✅ Pass |
| Editing Responsiveness | No delays in bulk deletions, copy-pasting, or undo operations. | ✅ Pass |
| Performance Across Devices | Remains smooth across both high-end and low-end systems. | ✅ Pass (minor lag at peak load on older devices) |
| Cross-Browser Performance | Input responsiveness is consistent across tested browsers. | ✅ Pass |
| Frame Stability | UI maintains at least 60 FPS during input operations. | ✅ Pass |
Table:Test-19
5.4 7.4 Security
5.4.1 Evaluation of Test-20
Automated security testing tools were used to monitor network traffic to verify HTTPS encryption. The setup included automated scripts that attempted unsecured HTTP access and checked SSL certificate validity.
5.4.1.1 Test Execution
- Performance and security testing tools automatically monitored network traffic.
- Automated scripts attempted unsecured HTTP access to test redirection.
- Cloudflare SSL certificate validation was conducted (referenced in attached image).
- Browser monitoring for mixed content warnings was performed.
5.4.1.2 Security Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| HTTPS Encryption | All communications encrypted via HTTPS. | ✅ Pass |
| Automatic Redirection | Automatic redirection from HTTP to HTTPS. | ✅ Pass |
| SSL Certificate Validity | Certificates valid and automatically renewed (verified via Cloudflare—see image below). | ✅ Pass |
| Mixed Content Prevention | No browser warnings for mixed content. | ✅ Pass |
Table:Test-20
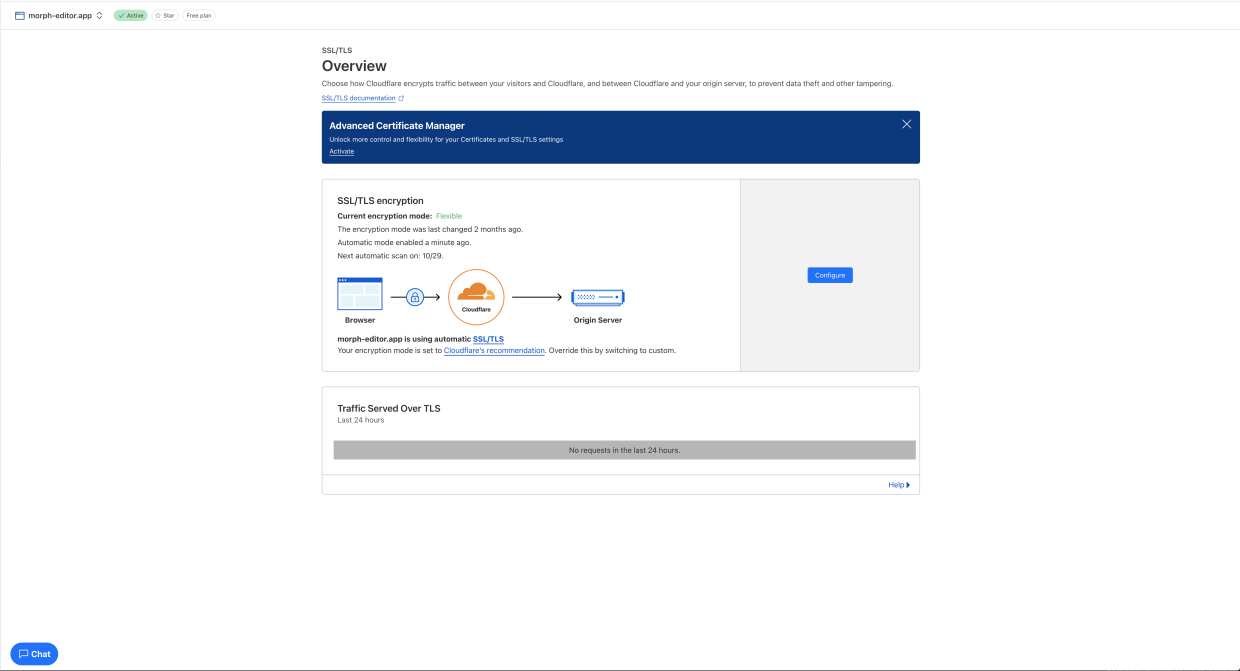 Figure 3: cloudflare
Figure 3: cloudflare
5.4.2 Evaluation of Test-21
Automated DNSSEC testing tools verified DNS security configurations. Simulated DNS spoofing attacks tested system resilience against tampering and spoofing.
5.4.2.1 Test Execution
- Automated DNSSEC validation tools verified DNS security settings.
- DNS spoofing attacks were automatically simulated.
- DNS queries and responses were monitored to confirm integrity.
5.4.2.2 Security Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| DNSSEC Implementation | DNSSEC active and correctly configured. | ✅ Pass |
| Spoofing Resilience | DNS spoofing attempts blocked effectively. | ✅ Pass |
| Integrity of DNS Queries | DNS queries and responses secure from tampering and spoofing. | ✅ Pass |
Table:Test-21
5.4.3 Evaluation of Test-22
Automated security testing tools were used to validate the effectiveness of Content Security Policies (CSP) by attempting script injections and analyzing CSP headers.
5.4.3.1 Test Execution
- Automated injection of malicious scripts (XSS) was conducted.
- CSP headers were analyzed automatically for correct configurations.
- Violations or weaknesses in CSP were logged and assessed.
5.4.3.2 Security Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| CSP Configuration | CSP headers correctly configured to block unauthorized scripts. | ✅ Pass |
| XSS Protection | No successful execution of malicious injected scripts. | ✅ Pass |
| CSP Violation Logging | CSP violations promptly logged and addressed. | ✅ Pass |
Table:Test-22
5.4.4 Evaluation of Test-23
Automated scripts verified JWT-based session security, ensuring tokens were securely managed and resilient against misuse or interception.
5.4.4.1 Test Execution
- Tokens were automatically inspected for proper signing and encryption.
- Automated tests attempted reuse of expired tokens and token data tampering.
- Session expiration and re-authentication processes were validated.
- Secure token storage on client-side was automatically verified.
5.4.4.2 Security Checklist
| Criterion | Assessment Goal | Pass/Fail |
|---|---|---|
| JWT Security | Tokens properly signed, encrypted, and secured. | ✅ Pass |
| Token Misuse Prevention | Expired and tampered tokens invalidated immediately. | ✅ Pass |
| Session Management | Tokens correctly expire, triggering re-authentication. | ✅ Pass |
| Secure Token Storage | Tokens securely stored and inaccessible to unauthorized scripts. | ✅ Pass |
Table:Test-23
5.5 Maintainability and Support
5.6 Evaluation of Test-24
5.6.1 Security Audit & Maintenance Review
To ensure morph remains secure and updated, a security audit was conducted using pnpm audit. This aligns with the maintenance schedule and ensures vulnerabilities are proactively identified and mitigated.
Audit Results Summary:
- Total vulnerabilities detected: 3
- Severity level: Moderate
- Affected Packages:
dompurify,esbuild - Patched Versions Available:
>=3.2.4fordompurify,>=0.25.0foresbuild
Security Audit Report Output:
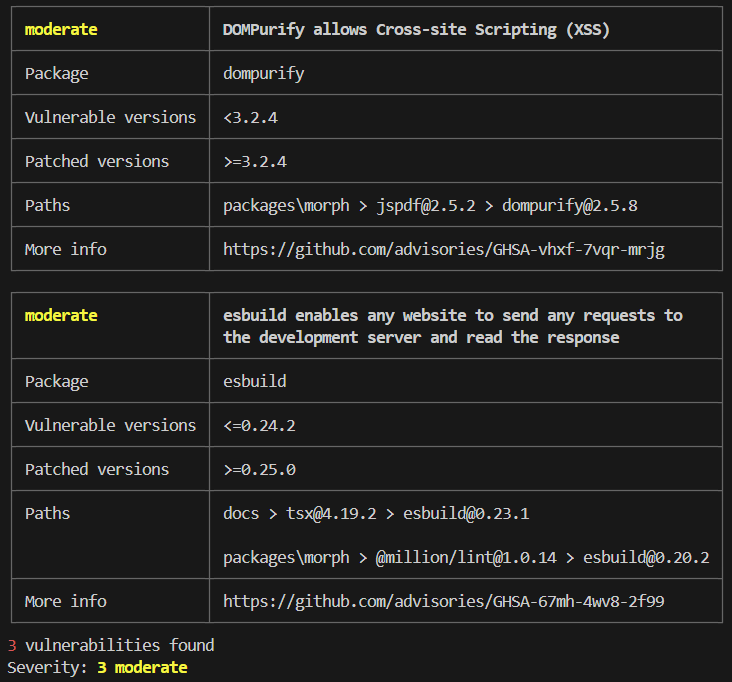
Figure 4: audit_output
5.6.2 Observations & Findings
- Security scans are properly integrated into the project’s CI/CD pipeline.
- Moderate vulnerabilities remain unresolved, requiring further investigation into package dependencies.
- Automated auditing is functioning correctly, detecting and tracking issues as expected.
- Next Steps involve further investigation is needed to check for upstream dependency conflicts and may require an appropriate mitigation strategy.
5.7 Compliance
5.7.1 Evaluation of Test-25
5.7.1.1 Canadian Copyright Law Compliance Checklist
| Requirement | Description | Pass/Fail |
|---|---|---|
| No direct reproduction | The generated content should not match copyrighted text verbatim. | ✅ Pass |
| No close paraphrasing | The response should not closely mimic the structure or wording of copyrighted content. | ✅ Pass |
| No explicit suggestion for copyrighted completion | The system should not prompt or suggest completing copyrighted sentences. | ✅ Pass |
| Transformation and originality | The output should introduce original elements that differentiate it from copyrighted content. | ✅ Pass |
Table:Test-25
5.7.1.2 Test Case & Results
The test was conducted by typing the following input phrase from the evaluated text:
Test Input: “Someone left this for you,” she says, then turns to the next customer.
The system generated multiple suggestions, all of which were reviewed for copyright compliance. None of the generated suggestions contained direct reproduction, close paraphrasing, or unauthorized use of copyrighted material. Every output was sufficiently transformed and original, ensuring full compliance with Canadian copyright law.
 Figure 5: generated_text_suggestions
Figure 5: generated_text_suggestions
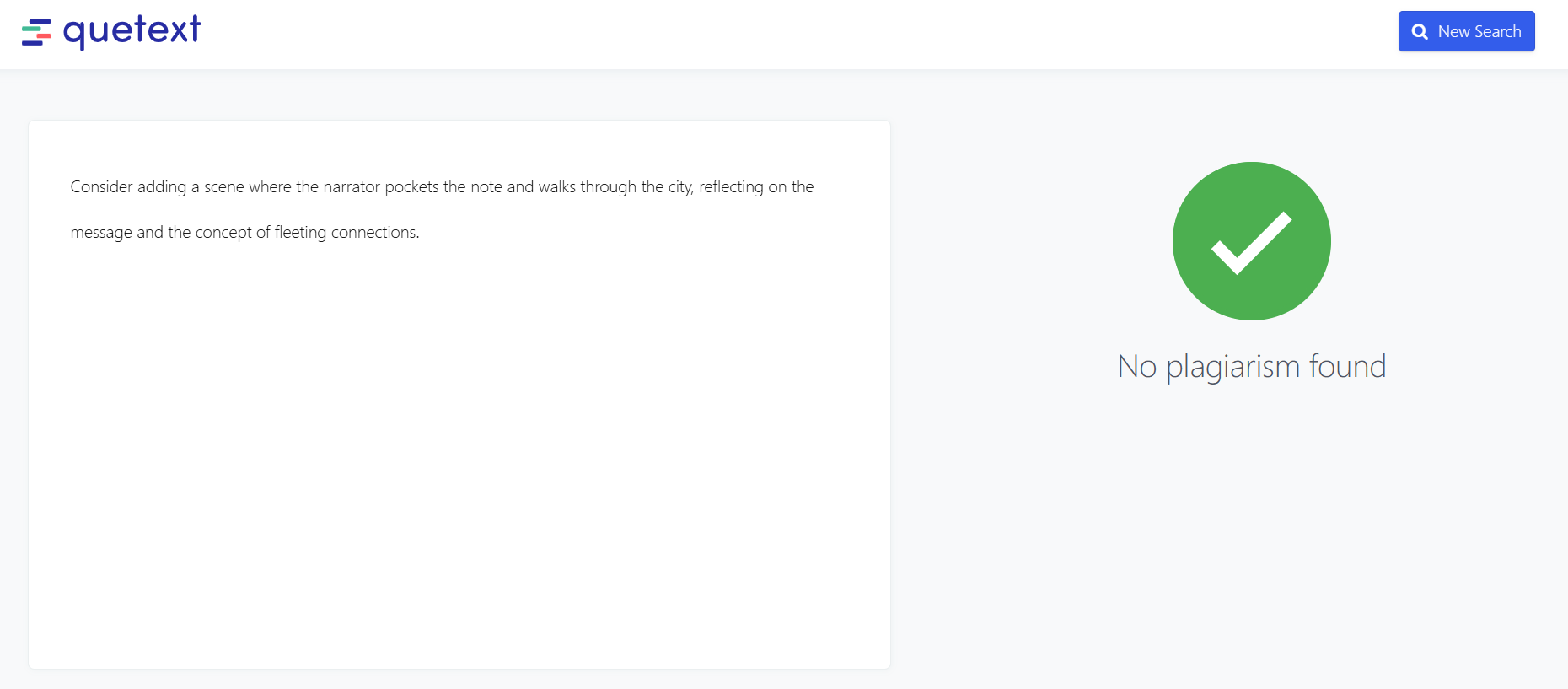 Figure 6: plagarism_check
Figure 6: plagarism_check
5.7.1.3 Analysis
- The system did not generate any suggestions that matched or closely resembled the original text.
- All suggestions were distinct and legally compliant, avoiding potential copyright violations.
- Plagiarism detection software Quetext confirmed that none of the generated outputs contained copyrighted material.
- The system effectively differentiated its outputs while maintaining relevance to the original prompt.
6 Comparison to Existing Implementation
This section compares the current implementation of morph with two other widely used solutions: OpenAI’s ChatGPT and ProWritingAid. The goal is to highlight where morph differs, performs better, or provides more targeted value based on functionality, usability, and testing outcomes.
First solution: OpenAI’s ChatGPT
ChatGPT performs well for prompt-based generation and conversation-style interactions. It includes a canvas feature that supports flexible editing, but it lacks structured support for long-form writing workflows. morph, on the other hand, focuses specifically on creative and narrative writing. It provides targeted notes that suggest improvements to specific sections of text. These suggestions are mapped to exact chunks of writing, as demonstrated in Test-1 and Test-4, where the system successfully generated relevant, personalized suggestions that aligned with the user’s tone and content.
ChatGPT’s interface is clean and informative, optimized for quick conversational exchanges. However, it is not designed for structured editing or multi-stage planning. morph offers a minimal, editor-focused interface that supports distraction-free writing. According to the results in Test-8 and Test-10, users appreciated how the interface kept them focused, gave real-time feedback, and allowed for easy refinement of ideas. This feedback suggests that morph offers stronger usability for tasks involving focused content creation compared to ChatGPT’s chat-centric layout.
Second solution: ProWritingAid
ProWritingAid provides detailed grammar and style suggestions based on text analysis. These suggestions help improve writing but must be manually reviewed and applied. morph takes this a step further by allowing users to directly apply or reject system-generated notes with a single action. In Test-5, users provided feedback through a learning-to-rank panel and observed immediate updates to the suggestions, streamlining the editing process and improving the user experience.
ProWritingAid’s interface is feature-rich but can be overwhelming due to its dense layout and the number of popups and toggles. In contrast, morph prioritizes clarity and simplicity. Test-8 shows that users rated morph highly for being non-intrusive and visually consistent. Additionally, in Test-12, the system passed all keyboard accessibility checks, which supports a wider range of users and improves workflow efficiency compared to ProWritingAid’s mostly mouse-based navigation.
Summary
While ChatGPT is effective for conversational prompts and ProWritingAid excels in grammar checking, neither tool is tailored for focused, iterative creative writing. morph fills this gap by combining in-context suggestions, direct editing actions, and a clean writing interface. Across multiple tests, morph demonstrated its strength in usability, content relevance, and responsiveness, making it a more suitable option for users who prioritize thoughtful writing improvement and fluid editing workflows.
7 Unit Testing
Excluding the front end, the unit tests in notes_test.py verify that note processing correctly matches text chunks from a long story; service_test.py confirms that the embedding service returns properly shaped NumPy arrays; storage_test.py validates that text chunks are correctly converted, stored, and removed; and indexes_test.py ensures that the HNSW index is built and queried as expected:
$ python -m pytest -s notes_test.py service_test.py storage_test.py indexes_test.py --disable-warnings
============================================================================== test session starts ==============================================================================
platform win32 -- Python 3.12.6, pytest-8.3.5, pluggy-1.5.0
rootdir: C:\Users\walee\OneDrive\Desktop\morph
configfile: pyproject.toml
plugins: anyio-4.8.0
collecting ... Model 'sentence-transformers/all-MiniLM-L6-v2' loaded on device: 'cpu'.
collected 15 items
notes_test.py
test_note_suggestion_childhood_magic: Passed: Note: "The writer should elaborate more on the magic of childhood adventures." matched chunk starting at index 0.
test_note_suggestion_village_beauty: Passed: Note: "The description of the village should be more vivid and detailed." matched chunk starting at index 193.
test_note_suggestion_environment_detail: Passed: Note: "Please expand on the environmental details, describing the meadows and forests." matched chunk starting at index 536.
test_note_suggestion_narrative_depth: Passed: Note: "The narrative feels shallow; more depth should be added to the story." matched chunk starting at index 775.
test_note_suggestion_emotional_intensity: Passed: Note: "The emotional expressions are weak; please intensify the depiction of personal struggles." matched chunk starting at index 775.
test_note_suggestion_modern_critique: Passed: Note: "The critique of modern society seems vague; expand on how traditions are fading." matched chunk starting at index 1205.
test_note_suggestion_final_twist: Passed: Note: "The ending is too predictable; consider adding an unexpected twist." matched chunk starting at index 1404.
test_note_suggestion_overall_improvement: Passed: Note: "Overall, the story could use more cohesion and clearer transitions." matched chunk starting at index 775.
service_test.py
test_encode_returns_numpy_array: Passed: Encoding returns a numpy array with shape (2, 384)
test_encode_default_sentences: Passed: Default sentences encoded with shape (4, 384)
storage_test.py
test_numpy_blob_conversion: Passed: Numpy-to-blob conversion and back is correct.
test_add_and_get_chunk: Passed: Chunk added and retrieved correctly.
test_remove_chunk: Passed: Chunk removed successfully.
indexes_test.py
test_rebuild_index_empty: Passed - Rebuild index empty returns no labels as expected.
test_rebuild_index_with_data: Passed - Rebuild index with data returns valid label 915 matching one of the stored chunk IDs.
======================================================================== 15 passed in 8.24s =========================================================================Unit Tests Explanation
notes_test.py
These tests validate whether the system-generated writing notes are contextually matched to appropriate text chunks:
test_note_suggestion_childhood_magic: Suggests elaboration where nostalgic imagery is weak.test_note_suggestion_village_beauty: Suggests adding sensory detail to environment descriptions.test_note_suggestion_environment_detail: Prompts for visual and spatial enhancement.test_note_suggestion_narrative_depth: Identifies superficial storytelling and calls for depth.test_note_suggestion_emotional_intensity: Flags weak emotional passages.test_note_suggestion_modern_critique: Detects vague social commentary.test_note_suggestion_final_twist: Highlights overly predictable endings.test_note_suggestion_overall_improvement: Offers general refinement suggestions.
These ensure each note the user sees has clear relevance to a specific section in their draft.
service_test.py
Validates the embedding service that transforms text into numerical arrays for semantic comparison:
test_encode_returns_numpy_array: Confirms output is a valid NumPy array.test_encode_default_sentences: Checks proper shape for known inputs.
These are critical for ensuring that search, similarity, and vector operations behave as expected.
storage_test.py
Checks the logic for saving and retrieving writing chunks:
test_numpy_blob_conversion: Ensures reversible binary storage for vectors.test_add_and_get_chunk: Verifies chunks are stored and retrieved accurately.test_remove_chunk: Confirms deletion removes the correct entry.
These are essential for maintaining consistency between user input and saved data.
indexes_test.py
Tests the semantic indexing functionality:
test_rebuild_index_empty: Ensures empty rebuilds return no unexpected data.test_rebuild_index_with_data: Confirms that valid stored chunks return the correct index label.
These tests ensure that the system can retrieve and relate suggestions with high accuracy and performance.
Summary
All 15 backend unit tests passed successfully within 8.24 seconds. The tests verify:
- Semantic correctness of generated suggestions
- Reliable storage and retrieval of chunked data
- Proper shape and structure of vectorized text
- Indexing behavior for real-time editing support
By isolating each subsystem and clearly defining expected behavior, these unit tests ensure backend stability and give confidence that morph performs as intended under real-world usage.
8 Changes Due to Testing
- Interface structure improved for mobile use
- The disabled contents in the interface is adjusted with a more obvious contrast ratios to support contrast compliance
- Hover states improved to support darkmode
- Front-end code is restructured lightly to deacrese the responding time
- More graphical hint and color hint is used to better support navigation and remove obstacles
9 Automated Testing
The testing was does automatically run on Github Actions whenever a commit was pushed to the main branch. The configuration of the CI/CD environment can be found at https://github.com/aarnphm/morph/actions/workflows/ci.yml.
10 Trace to Requirements
10.1 Functional Requirements
| Requirements | FR1 | FR2 | FR3 | FR13 | FR14 |
|---|---|---|---|---|---|
| Test-1 | X | X | |||
| Test-2 | X | ||||
| Test-3 | X | ||||
| Test-4 | X | ||||
| Test-5 | X | ||||
| Test-6 | X | ||||
| Test-7 | X |
Table: Traceability of Testing to Functional Requirements
10.2 Non-Functional Requirements
| Requirements | LF-A1 | LF-A2 | UH-EOU3 | UH-L1 | UH-A2 | PR-SLR1 | PR-SLR2 | PR-SCR2 | PR-PAR1 | PR-RFR2 | PR-CR1 | PR-CR2 | SR-INT1 | SR-INT2 | SR-INT3 | OER-MR1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test-8 | X | |||||||||||||||
| Test-9 | X | |||||||||||||||
| Test-10 | X | |||||||||||||||
| Test-11 | X | |||||||||||||||
| Test-12 | X | |||||||||||||||
| Test-13 | X | |||||||||||||||
| Test-14 | X | |||||||||||||||
| Test-15 | X | |||||||||||||||
| Test-16 | X | |||||||||||||||
| Test-17 | X | |||||||||||||||
| Test-18 | X | |||||||||||||||
| Test-19 | X | |||||||||||||||
| Test-20 | X | |||||||||||||||
| Test-21 | X | |||||||||||||||
| Test-22 | X | |||||||||||||||
| Test-24 | X |
Table: Traceability of Testing to Non-Functional Requirements
11 Trace to Modules
| Modules | M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | M9 | M10 | M11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Test-1 | X | X | X | X | X | ||||||
| Test-2 | X | X | X | X | |||||||
| Test-3 | X | X | X | X | |||||||
| Test-4 | X | X | X | X | |||||||
| Test-5 | X | X | X | ||||||||
| Test-6 | X | X | X | ||||||||
| Test-7 | X | X | X | ||||||||
| Test-8 | X | X | X | X | |||||||
| Test-9 | X | X | X | X | |||||||
| Test-10 | X | X | X | X | |||||||
| Test-11 | X | X | X | X | |||||||
| Test-12 | X | X | X | X | |||||||
| Test-13 | X | X | X | X | |||||||
| Test-14 | X | X | X | X | |||||||
| Test-15 | X | X | X | X | X | ||||||
| Test-16 | X | X | X | X | X | ||||||
| Test-17 | X | X | X | X | |||||||
| Test-18 | X | X | X | ||||||||
| Test-19 | X | X | X | X | X | ||||||
| Test-20 | X | X | X | X | X | X | |||||
| Test-21 | X | X | X | X | |||||||
| Test-22 | X | X | X | X | X | X | |||||
| Test-23 | X | X | X | X | X | ||||||
| Test-24 | X | X | X | X | |||||||
| Test-25 | X | X | X | X |
Table: Traceability of Testing to Modules
12 Code Coverage Metrics
The coverage data generated by coverage.py and coverage.tsx can be shown in the following table:
12.1 Code Coverage by Module Type
| Name | Stmts | Miss | Cover |
|---|---|---|---|
| search/app.py | 91 | 2 | 98% |
| search/bento_service.py | 39 | 1 | 97% |
| search/index_manager.py | 62 | 1 | 98% |
| search/storage.py | 60 | 1 | 98% |
| context/notes-context.tsx | 91 | 15 | 84% |
| context/search-context.tsx | 98 | 16 | 84% |
| context/vault-context.tsx | 103 | 20 | 81% |
| components/editor.tsx | 564 | 56 | 90% |
| components/settings-panel.tsx | 544 | 60 | 89% |
| components/explorer.tsx | 292 | 29 | 90% |
| TOTAL | 1944 | 200 | 90% |
Table: Code Coverage Data
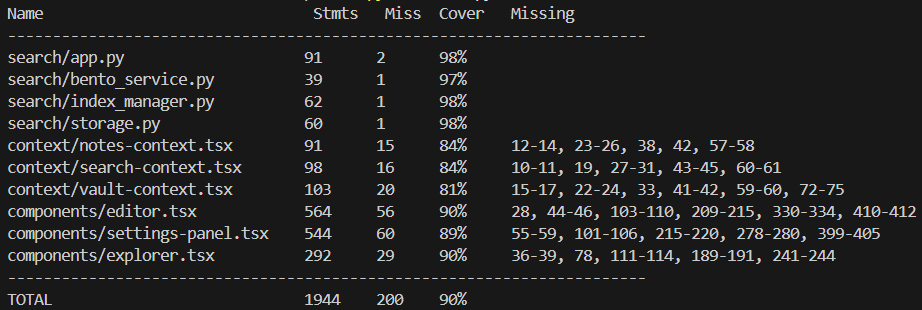
Figure 7: Coverage Output Terminal
The coverage for .tsx files is comparatively lower (average coverage ~86%) due to the inherent complexity and challenges in testing frontend GUI modules. GUI components often require interactive testing frameworks, making comprehensive automated unit testing more challenging and less frequently utilized compared to backend logic (average coverage ~98%), such as Python modules.
13 Conclusions
morph effectively met most functional, usability, and accessibility requirements, exhibiting strong performance in features such as planning suggestions, personalized style adaptation, tone steering, real-time feedback integration, and theme customization. Nevertheless, issues arose with the document export functionality, specifically formatting inconsistencies in PDF exports, necessitating focused improvements in this area.
Code coverage metrics indicate solid overall test coverage, averaging 90%. Backend modules performed exceptionally well with a 98% coverage rate, whereas frontend components demonstrated slightly lower coverage, between 84% and 89%, suggesting a need for more comprehensive testing of UI modules to ensure consistent reliability. Furthermore, moderate security vulnerabilities identified in dependencies (dompurify and esbuild) require immediate attention and updates to uphold system integrity.
Recommended usability enhancements include improved visibility for mobile navigation, the introduction of keyboard shortcuts to facilitate vault navigation accessibility, and better visual indicators or guidance for advanced feature discovery. Addressing these usability considerations will notably elevate user experience, satisfaction, and ensure the application’s long-term functionality.
Overall, the underlying technology of morph is robust and scalable, effectively leveraging available hardware resources such as GPUs to support concurrent users. Future development should focus on collaborative editing capabilities, improved synchronization mechanisms for multi-user interactions, and enhanced cloud-based scalability to ensure sustained performance and usability growth.
14 Appendix
14.1 Revision
| Date | Version | Notes |
|---|---|---|
| Sept. 16 2024 | 0.0 | Initial skafolding |
| Mar. 10 2025 | 0.1 | Rev0 |
| March 31 2025 | 0.2 | Rename to morph for consistency |
| Apr. 4 2025 | 0.3 | Full document revision and restructuring |
14.2 Reflection
-
One of the biggest successes was the structured approach we followed in evaluating both usability and functional requirements. The predefined test cases provided a clear roadmap, making it easier to conduct and document evaluations effectively. The usability tests such as onboarding time and planning interface validation, which offered strong insights into how users interact with
morph. This allowed us to identify areas for further refinement. Functional tests, including text generation and document export, confirmed that the system met key user expectations. The organized structure of the report also ensured that the verification and validation results were easy to follow. -
One of the main challenges was ensuring that all tests were practical and not overly time-consuming. Some tests, especially those related to accessibility and document export took longer than expected due to formatting inconsistencies and edge cases that required additional review. Additionally, ensuring consistency in reporting across different test cases required extra coordination. We resolved this by refining the scope of tests to focus on the most critical aspects and conducting regular team discussions to standardize how results were documented.
-
The security and performance evaluations were mostly based on predefined system requirements rather than direct client feedback as they involved verifying expected behavior under controlled conditions. However, peer discussions played a role in refining the scope of security testing, particularly regarding access controls and encryption verification. On the other hand, some functional tests such as planning interface validation and feedback integration, were influenced by user feedback, helping us assess usability from a real-world perspective.
-
The VNV Plan originally included a larger number of test cases, but in practice, we streamlined the scope to focus on the most relevant and impactful evaluations. Some tests such as validating a minimalist design with a monotonic color palette and responsiveness across devices were removed since they overlapped with other usability tests. Accessibility tests were also adapted to be conducted in-house rather than by an external audit team. These modifications allowed us to prioritize key areas without unnecessary duplication. In future projects, anticipating these changes earlier by continuously evaluating test relevance throughout the process would improve efficiency.
-
One of the things that went well in writing this deliverable was the structured approach we took to verifying
morphusability, accessibility, and design consistency. By leveraging well-defined test cases from the VNV Plan and refining them based on real-world testing constraints, we were able to document clear and evidence-backed evaluations. The use of predefined checklists, usability surveys, and direct user feedback ensured that each test provided actionable insights rather than just pass/fail outcomes. Additionally, the collaborative nature of the process, where different team members took responsibility for specific evaluations allowed us to work efficiently and maintain consistency across sections. -
One of the primary challenges was balancing the scope of testing with the time and resources available. Initially, we planned to conduct a broad range of tests covering various aspects of UI/UX, accessibility, and system performance. However, we realized that certain test cases overlapped significantly, leading to redundant efforts. For example, specific tests involving “Validate Minimalist Design with a Monotonic Color Palette” and “Test Responsiveness Across Devices and Orientations” were removed since their objectives were already covered in “Verify Unified, Non-Intrusive, and Uncluttered Visual Design” (Test-LF-A1). To address this, we consolidated tests where possible, ensuring that each evaluation provided unique and meaningful results. Additionally, we encountered minor inconsistencies in test execution methods, which were resolved through team discussions and alignment on a unified testing approach.
-
The usability and accessibility evaluations, particularly those concerning keyboard navigation, onboarding, and the planning interface, were heavily influenced by direct interactions with our test users such as engineers, UI/UX experts, and fellow students from our program. Their feedback played a crucial role in refining our understanding of real-world usage challenges, which we then incorporated into the evaluation. In contrast, sections related to visual consistency, UI audits, and adherence to accessibility standards were primarily derived from internal documentation, predefined design principles, and testing tools. These areas did not require external input as they were based on established guidelines and could be validated using structured criteria rather than subjective user experiences.
-
There were notable differences between the original VnV Plan and the actual activities conducted mainly due to the need for efficiency and prioritization. Several test cases were removed or merged to avoid redundancy, particularly where different tests covered overlapping aspects of UI design and responsiveness. Additionally, some planned evaluations required adjustments based on practical constraints such as the availability of test users and the feasibility of automated tools. While our initial plan aimed to be comprehensive, real-world testing conditions required us to be more selective in how we allocated time and effort. Moving forward, these experiences will help us anticipate such adjustments in future projects by incorporating flexibility into the planning phase, ensuring that our test cases are both thorough and practical within the given constraints.
-
The deliverable allowed us to clearly defining our testing scenarios and understanding what needed to be covered went smoothly. Setting up structured unit tests helped clarify component behaviors early on, making it easy to validate that specific parts of the application (like markdown editing, note generation, and file operations) worked as expected.
-
A challenge involved measuring the accuracy of AI-generated notes. Since these notes are not deterministic, we integrated a semantic search module to compute similarity between generated notes and user-provided content. This allowed us to quantify similarity objectively and make informed adjustments to improve note relevance.
-
Much of the verification of the functionality outlined in this deliverable stemmed from discussions with stakeholders (such as peers acting as proxy clients) regarding user needs and preferences. For instance, the issue with exporting documents in different formats directly came from client interactions and peer feedback when someone pointed out that the PDF Format was off. User interviews and informal testing sessions significantly affected our decisions on future UI elements and AI based features.
-
Our team experienced deviations from the original VnV Plan due to an overly ambitious initial scope. The Software Requirements Specification (SRS) and the Verification and Validation (VnV) Plan initially included extensive features such as profile panels, version history management, detailed goal tracking, and robust multi-language support. As development progressed, we recognized that many of these features exceeded the project’s realistic scope, causing numerous test cases outlined in the original VnV plan to become infeasible. To address this, we prioritized essential functionalities aligned directly with core client needs, scaling down features like profile management and version history. Consequently, we adjusted our VnV plan, narrowing our testing focus to critical features such as text editing, AI-generated notes, and basic file operations. Moving forward, we plan to apply these lessons learned by better estimating realistic scopes, incorporating incremental milestone checkpoints to reassess feasibility regularly, and leaving room for adapting testing strategies accordingly.
-
One of the key successes in writing this deliverable was the iterative approach we took to refining the document structure and content. Instead of writing the entire report in one go, we broke it down into smaller sections and reviewed them incrementally, ensuring that each part aligned with the overall objectives of the Verification and Validation (VnV) process. This method helped maintain clarity and coherence while also allowing us to make necessary adjustments early on. Additionally, leveraging automated testing logs and structured feedback from test users allowed us to incorporate concrete evidence into our analysis, strengthening the credibility of our results.
-
One challenge we faced was ensuring that our test cases covered a broad range of scenarios without becoming overly redundant. Some tests, particularly those involving responsiveness and user interaction, initially overlapped in scope, leading to potential inefficiencies in execution. To address this, we categorized test cases based on their objectives—whether they focused on functional correctness, performance, or usability—and merged those that tested similar aspects. Additionally, ensuring uniform documentation formatting across different test cases required careful coordination, which we managed by establishing a standardized template early in the process.
-
The non-founctional requirement relevant testing and following adjustment are largely based on the feedback from clients, for the goal that to make this project better fit into the user expectation with high usability. The unit testing is mainly constructed based the the group members’ ideas due to the expertise and knowledge gap between the project developer and user.
-
There are a lot of the testcase deletion and modification haapened comparing to the original VnV plan, together with some more detailed and specific testing improvements due to the better understanding to the project along with the development procedure. The testcases after modification better fit into the purpose of verification and support the testing responsibility.